

Bobby Axelrod, the main character on the popular Finance drama, Billions, is a lot like Tesla CEO Elon Musk. They’re both billionaires. They both draw substantial public praise and criticism and are highly divisive figures who have a large impact on their respective industries. They were also both investigated and charged by the SEC (and in Axelrod’s case, the US Justice Department) for actions related to securities law. The main difference between the two? Bobby Axelrod is a fictional character whose proclivity for conflict is only superceded by his complete lack of restraint when his life and freedom are on the line. In real life, the consequences of your actions are permanent and making deals in the business world often means compromising, negotiating, and settling.
Today (September 29, 2018) Elon Musk settled with the SEC. He will no longer be chairman of Tesla, for at least three years, and will pay a fine in excess of $20 Million. In all, it is a relatively lesser penalty than the lifetime ban from being CEO of a publicly traded company that the SEC was seeking. It is also a larger punishment than someone who has not committed any wrongdoing deserves. Depending on your perspective, Musk either got away easy or was unfairly chastised by the state for a 60 character tweet.
Of course, the civil settlement does not preclude the Justice Department from filing criminal charges against Elon at a future date. However, a criminal trial has a much higher burden of proof than a civil case, which can be decided based on a balance of probabilities. In a criminal case, the prosecution must prove, beyond a reasonable doubt, that the defendant committed the alleged crimes, whereas, in a civil suit, all that is required is a greater than 50% probability that the act took place.
In a previous post from September 27, we discussed whether AI could play a role in predicting the outcome of cases like this, perhaps assisting traders in making appropriate investment decisions surrounding companies with legal troubles. Despite a strong performance in short-term volume trading, automation has not yet played a large role in the fundamental analysis of a stock’s long-term viability. Most AIs that trade today are relying on purely technical analysis, not looking at any of the traits that make a company likely to succeed, but instead relying on historical price data to predict trading and movement patterns.
Fundamental analysis is complex and subjective. Even the smartest deep neural networks would have a difficult time distinguishing between the very human aspects that go into valuing a company. The problem with AI, in this particular application, is that it would require a broad knowledge of various domains to be combined in order to predict with any degree of accuracy. Right now, even the best deep neural networks are still very narrowly defined. They are trained to perform exceptionally well within certain contexts, however, beyond the confines of what they ‘understand’ they are unable to function at even a basic level.

In the above example, we can see how more complicated neural networks might fail to understand topics that are even slightly different from what they have seen in the past. The model fits the data that the network has already encountered, however, this data does not reflect what could happen in the future. When something happens that they haven’t encountered before (a CEO tweets something about 420, for example), a human can immediately put that into context with our everyday experience and understand that he’s likely talking about smoking weed. However, an AI trained to predict share prices based on discounted cash flow analysis would have absolutely no clue what to do with that information.
It is likely that there are companies working on technology to help train neural networks to deal with the idiosyncratic information present in everyday business interactions. One possible answer is to have multiple neural networks working on different subsets of the problem. Similar to how deep neural networks have enabled advances in fields ranging from medical diagnosis to natural language processing, new organizations of these systems could enable the next generation of AI that is able to handle multiple tasks with a high level of competency. As we continue to build this technology, we’ll keep speculating on whether or not an executive is guilty, and traders and short-sellers will continue to make and lose billions based on the result.














 , the market’s rate of return because if we choose not to put the money towards an MBA, we could instead put it in an
, the market’s rate of return because if we choose not to put the money towards an MBA, we could instead put it in an 
 in order to account for the
in order to account for the 
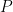 , is $87,500, our discount rate,
, is $87,500, our discount rate, , is 5% and our number of periods,
, is 5% and our number of periods, 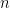 , is 2. That leaves us with the following:
, is 2. That leaves us with the following:![FV = \$87,500*[((1+0.05)^2-1)/0.05] = \$179,375](https://s0.wp.com/latex.php?latex=FV+%3D+%5C%2487%2C500%2A%5B%28%281%2B0.05%29%5E2-1%29%2F0.05%5D%C2%A0+%3D+%5C%24179%2C375+&bg=ffffff&fg=000&s=0&c=20201002)

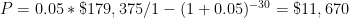





 atoms in the universe. A game of Go can last up to
atoms in the universe. A game of Go can last up to  moves, and at each point has at most 361 legal moves. From the lower bound, the
moves, and at each point has at most 361 legal moves. From the lower bound, the  , which is much, much larger than the number of atoms in the observable universe. This means that brute-forcing the outcome of a Go match is essentially impossible, even with the most powerful supercomputers in the world at your disposal.
, which is much, much larger than the number of atoms in the observable universe. This means that brute-forcing the outcome of a Go match is essentially impossible, even with the most powerful supercomputers in the world at your disposal.







