

Index funds are the most highly traded equity investment vehicles, with some funds like ones created by Vanguard Group cumulatively being valued at over $4 Trillion USD. Index funds have democratized investing by allowing access to passive investments for millions of people. But what are they?
An index fund is a market-capitalization weighted basket of securities. Index funds allow retail investors to invest in a portfolio made up of companies representative of the entire market without having to create that portfolio themselves. Compared to actively managed funds like mutual funds and hedge funds, index funds tend to have much lower fees because the only balancing that happens occurs based on an algorithm to keep the securities in the fund proportional to their market cap (market capitalization, or market cap, is the number of shares that a company has on the market multiplied by the share price).
Starting in the 1970s, the first ‘index funds’ were created by companies that tried to create equally weighted portfolios of stocks. This early form of the index fund was abandoned after a few months. It quickly became apparent that it would be an operational nightmare to be constantly rebalancing these portfolios to keep them equally weighted. Soon companies settled on the market capitalization weighting because a portfolio weighted by market cap will remain that way without constant rebalancing.
With the incredible advancement of AI and extraordinarily powerful computers, shouldn’t it be possible to create new types of ‘passively managed’ funds that rely on an algorithm to trade? What that could mean is that index funds might not have to be market cap weighted any longer. This push is actually happening right now and the first non-market cap weighted index funds to appear in over 40 years could be available to retail investors soon.
But this means that we need to redefine the index fund. The new definition has three criteria that must be met for a fund to meet:
- It must be transparent – Anyone should be able to know exactly how it is constructed and be able to replicate it themselves by buying on the open market.
- It must be investable – If you put a certain amount of money in the fund, you will get EXACTLY the return that the investment shows in the newspapers (or more likely your iPhone’s Stocks app).
- It must be systematic – The vehicle must be entirely algorithmic, meaning it doesn’t require any human intervention to rebalance or create.
So, what can we do with this new type of index fund?

We can think of investing like a spectrum, with actively managed funds like hedge funds on one side and passively managed index funds on the other and all the different parameters like alpha, risk control and liquidity as sliders on a ‘mixing board’ like the one in the image above. Currently, if we wanted to control this board, we would have to invest in expensive actively managed funds and we wouldn’t be able to get much granular control over each factor. With an AI-powered index fund, the possibilities of how the board could be arranged are endless. Retail investors could engage in all sorts of investment opportunities in the middle, instead of being forced into one category or another.

The implications of a full-spectrum investment fund are incredible. Personalized medicine is a concept that is taking the industry by surprise and could change the way that doctors interact with patients. Companies like Apple are taking advantage of this trend by incorporating new medical devices into consumer products, like with the EKG embedded into the new Apple Watch Series 4.
Personalized investing could be just as powerful. Automated portfolios could take into account factors like age, income level, expenses, and even lifestyle to create a portfolio that is specifically tailored to the individual investor’s circumstances.
So why can’t you go out and purchase one of these new AI
Well, unfortunately, the algorithms do not exist, yet. The hardware and software
All hope is not lost, however. New research into the concept of bounded rationality, the idea that rational decision making is limited by the extent of human knowledge and capabilities, could help move this idea forward. One of the founding fathers of artificial intelligence, Herbert Simon, postulated that AI could be used to help us understand human cognition and better predict the kinds of human behaviours that helped keep us alive 8,000 years ago, but are detrimental for wealth accumulation today.
By creating heuristic algorithms that can capture these behaviours and learning from big data to understand what actions are occurring, we may soon be able to create software that is able to accentuate the best human behaviours and help us deal with the worst ones. Perhaps the algorithm that describes humanity has already been discovered.





 ,
, , and
, and .
.






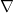 for short. Since we want to find the quickest way down, we actually want the negative gradient or
for short. Since we want to find the quickest way down, we actually want the negative gradient or  .
.